HOI-PAGE
Zero-Shot Human-Object Interaction Generation with Part Affordance Guidance
Given as input a set of 3D objects and a text prompt describing the desired interaction, our approach generates both human and object motion sequences performing the interaction in a zero-shot fashion. We distill part-level affordance from large language model reasoning as guidance, achieving flexible modeling of diverse interaction scenarios involving multiple people or objects.
Abstract
We present HOI-PAGE, a new approach that prioritizes part-level affordance reasoning to generate high-fidelity 4D human-object interactions (HOIs) from text prompts in a zero-shot fashion. In contrast to prior works that focus on global, whole body-object motion synthesis, our approach explicitly reasons about the underlying fine-grained mechanics of interactions using large language models (LLMs).
We capture this reasoning in a structured part affordance graph (PAG) representation, serving as a high-level interaction scaffolding to guide a three-stage synthesis: first, decomposing input 3D objects into semantic parts; then, generating reference HOI videos from text prompts to extract part-based motion constraints; and finally, optimizing for 4D HOI motion sequences that mimic the reference dynamics while satisfying part-level contact constraints.
Extensive experiments show that our approach is flexible and capable of generating complex multi-object or multi-person interaction sequences, with significantly improved realism and text alignment for zero-shot 4D HOI generation.
Video
Single-Person Multi-object Interaction Generation
Multi-person Single-Object Interaction Generation
How It Works
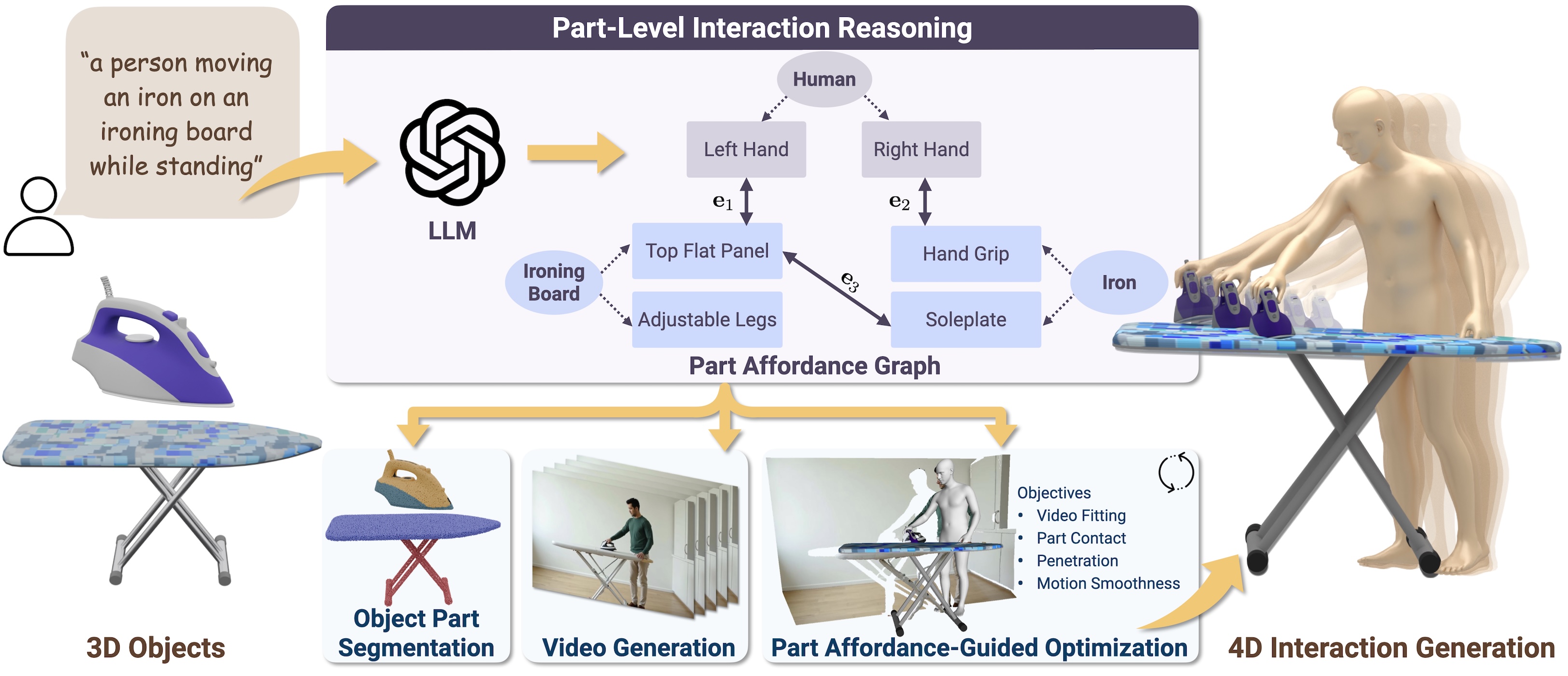
HOI-PAGE generates realistic 4D human-object interaction motions from a given set of 3D objects and a text prompt. We introduce Part Affordance Graphs (PAGs) to capture how specific object parts relate to human body parts (top-middle). The PAG is distilled from a large language model based on the text prompt and is used to guide a three-stage generation pipeline (bottom-middle):
- Decomposing the input objects into geometric parts based on multi-view detection and segmentation;
- Generating an HOI video from the text prompt and estimating object masks, depths, and 4D human motions;
- Optimizing for objects motions by fitting to the video while enforcing part-level contact constraints from the PAG.
Comparison to Baselines
Our part affordance-guided generations are more realistic and have better text alignment, when compared to baselines that only model overall full-body and object motions and require extensive captured interaction data for supervision.
HOI-PAGE Generalizes to Diverse Interaction Scenarios
Citation
@InProceedings{li2026hoipage,
title = {{HOI-PAGE}: Zero-Shot Human-Object Interaction Generation with Part Affordance Guidance},
author = {Li, Lei and Dai, Angela},
booktitle = {International Conference on Machine Learning},
year = {2026}
}Acknowledgements
This project is funded by the ERC Starting Grant SpatialSem (101076253), and the German Research Foundation (DFG) Grant "Learning How to Interact with Scenes through Part-Based Understanding."