GenZI: Zero-Shot 3D Human-Scene Interaction Generation
Given an arbitrary 3D scene, GenZI can synthesize virtual humans interacting with the 3D environment at specified locations from a brief text description. Our approach does not require any 3D human-scene interaction training data or 3D learning.
Abstract
Can we synthesize 3D humans interacting with scenes without learning from any 3D human-scene interaction data? We propose GenZI, the first zero-shot approach to generating 3D human-scene interactions. Key to GenZI is our distillation of interaction priors from large vision-language models (VLMs), which have learned a rich semantic space of 2D human-scene compositions.
Given a natural language description and a coarse point location of the desired interaction in a 3D scene, we first leverage VLMs to imagine plausible 2D human interactions inpainted into multiple rendered views of the scene. We then formulate a robust iterative optimization to synthesize the pose and shape of a 3D human model in the scene, guided by consistency with the 2D interaction hypotheses.
In contrast to existing learning-based approaches, GenZI circumvents the conventional need for captured 3D interaction data, and allows for flexible control of the 3D interaction synthesis with easy-to-use text prompts. Extensive experiments show that our zero-shot approach has high flexibility and generality, making it applicable to diverse scene types, including both indoor and outdoor environments.
Video
How It Works
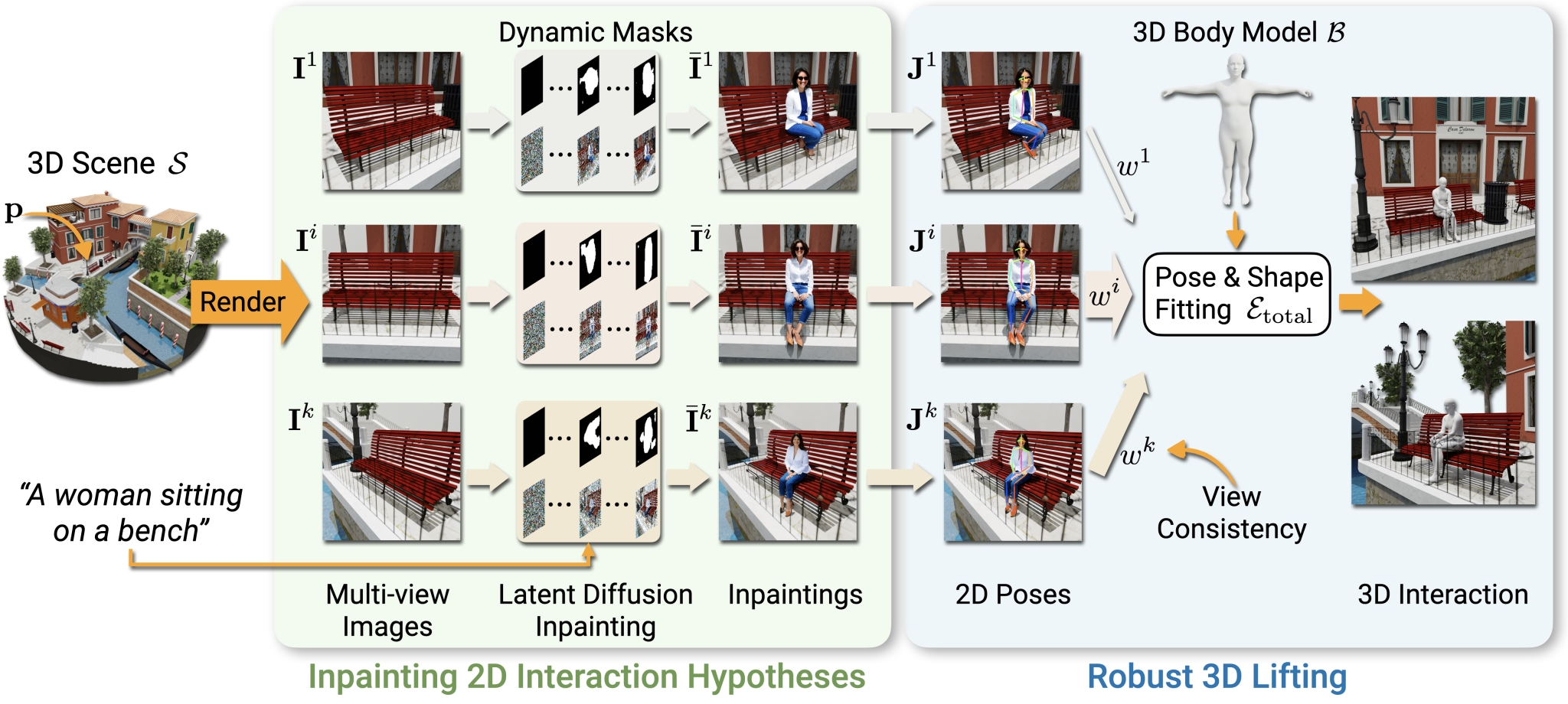
GenZI distills information from vision-language model for 3D human-scene interaction. We first leverage large vision-language models to synthesize possible 2D humans interactions with the 3D scene by employing latent diffusion inpainting on multiple rendered views of the environment at location p using our dynamic masking scheme to automatically estimate inpainting masks. We then lift these 2D hypotheses to 3D in a robust optimization for a 3D parametric body model (SMPL-X) that is most consistent with detected 2D poses in the inpainted 2D hypotheses. This produces a semantically consistent interaction that respects the scene context, without requiring any 3D human-scene interaction data.
Zero-Shot 3D Interaction Generations
Comparisons

GenZI synthesizes more realistic 3D human-scene interactions and generalizes better across scene types, when compared to baseline methods that are either trained on indoor interaction data or base on 3D human estimation from a single RGB image.
Citation
@InProceedings{li2024genzi,
title = {{GenZI}: Zero-Shot {3D} Human-Scene Interaction Generation},
author = {Li, Lei and Dai, Angela},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024}
}Acknowledgements
This project is funded by the ERC Starting Grant SpatialSem (101076253), and the German Research Foundation (DFG) Grant "Learning How to Interact with Scenes through Part-Based Understanding", and supported in part by a Google research gift.
We thank the following artists for generously sharing their 3D scene designs on Sketchfab.com: a Food Truck Project by xanimvm, WW2 Cityscene - Carentan inspired by SilkevdSmissen are licensed under CC Attribution-NonCommercial-NoDerivs. Bangkok City Scene by ArneDC, Low Poly Farm V2 by EdwiixGG, Low Poly Winter Scene by EdwiixGG, Modular Gym by Kristen Brown, 1DAE10 Quintyn Glenn City Scene Kyoto by Glenn.Quintyn, and Venice city scene 1DAE08 Aaron Ongena by AaronOngena are licensed under Creative Commons Attribution.